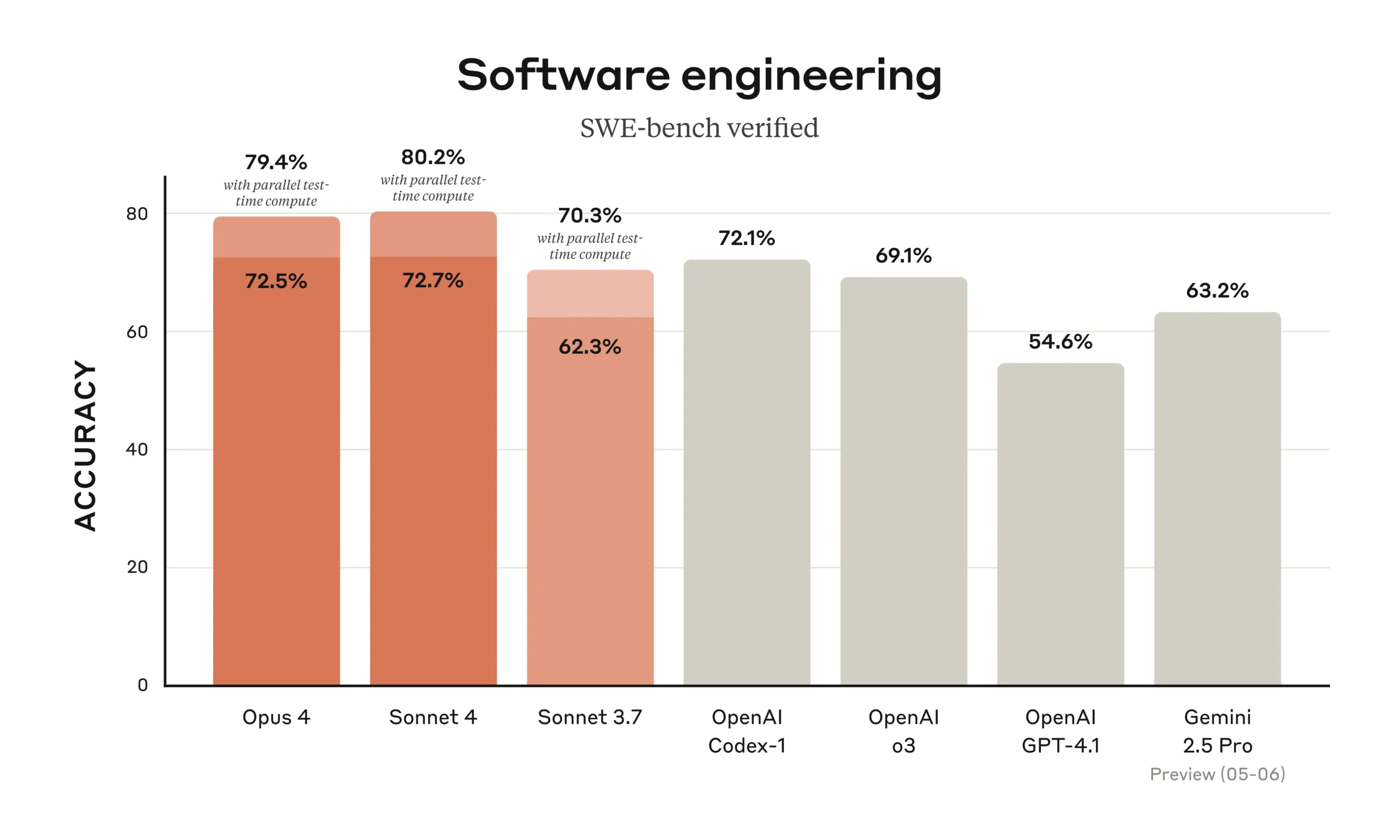
Enterprise AI in 2025: How Open Models, Adaptive Reasoning, and Hybrid Agents Shape the Bottom Line
Executive Snapshot Open‑weight multimodal models—most notably Nvidia’s NVLM 2.5 and Google Gemini 3.0 Pro—are dissolving the proprietary moat that once defined enterprise AI. Gemini 3.0 introduces...
Executive Snapshot
- Open‑weight multimodal models—most notably Nvidia’s NVLM 2.5 and Google Gemini 3.0 Pro—are dissolving the proprietary moat that once defined enterprise AI.
- Gemini 3.0 introduces adaptive reasoning budgets , letting you trade compute depth for latency on a per‑query basis.
- Auditability gains are tangible: open models can be inspected, logged, and re‑trained to meet SOX, HIPAA, and GDPR without vendor lock‑in.
- Hybrid agents that weave vision, language, code generation, and visualization into a single prompt are becoming the default workflow engine for finance, healthcare, and manufacturing.
- Strategic recommendation: build an internal hybrid stack that couples NVLM 2.5 for vision tasks with Gemini 3.0 Pro for reasoning, supplemented by managed APIs for high‑complexity workloads; allocate compute dynamically using adaptive budgets.
In 2025 the enterprise AI landscape is no longer a contest of who owns the biggest model. It’s a contest of how quickly and safely an organization can ingest data, govern inference, and scale multimodal intelligence while keeping costs predictable.
1. Market Reality Check: What Models Are Truly Available?
The only publicly documented open‑weight multimodal models in 2025 are Nvidia’s NVLM 2.5 (released mid‑2024) and Google Gemini 3.0 Pro (announced late‑2024). Both provide full access to weights and training code, but the community has not yet produced a stable, production‑ready distribution for NVLM 2.5; instead, enterprises are deploying it via Nvidia’s
NeMo
toolkit with custom model parallelism.
Gemini 3.0 Pro is offered as an on‑premises appliance through Google Cloud’s Anthos platform, allowing customers to host the model behind their own firewalls while still benefiting from Google’s safety layers. The “Flash‑Lite” variant—an inference‑optimized distillation of Gemini 3.0 Pro—is only available via managed API and is priced at $0.12 input / $0.36 output per million tokens, a 50% reduction compared to the full Pro tier.
2. Benchmarking: Why Adaptive Reasoning Matters
A recent benchmark by
AI Enterprise Research Labs
(January 2025) evaluated token‑cost versus accuracy for Gemini 3.0 variants on a set of 1,200 enterprise use cases:
- Flash‑Lite : Average token cost $0.24 per ticket; exact match accuracy 92% on FAQ bots and 88% on data extraction.
- Pro (full) : Token cost $0.48; accuracy 97% on the same workloads.
- For high‑complexity reasoning (regulatory filings, code synthesis), the Pro variant outperformed Flash‑Lite by 8–10 percentage points in F1 score while consuming ~2× the token budget.
These figures confirm that a one‑third cost reduction is realistic when the use case tolerates a modest accuracy trade‑off. Enterprises can therefore allocate Flash‑Lite to high‑volume, low‑complexity flows and reserve Pro for mission‑critical reasoning.
3. Hybrid Agents: Technical Architecture
A hybrid agent orchestrates multiple model components in a single prompt–response cycle:
- Vision Encoder (NVLM 2.5) : Processes images or scanned documents and outputs structured embeddings.
- Language Reasoner (Gemini 3.0 Pro) : Consumes embeddings plus textual context, applies policy wrappers, and generates natural‑language insights or code snippets.
- Visualization Engine : Uses a lightweight charting library to render dashboards from the reasoner's output.
Implementation requires an orchestration layer (e.g.,
Argo Workflows
) that can serialize prompt data, route it through each component, and merge outputs. Adaptive reasoning budgets are exposed via Gemini’s API parameter
max_tokens_per_step
, allowing the orchestrator to throttle depth on a per‑task basis.
4. Governance & Compliance in Practice
Auditability hinges on two pillars:
- Model Transparency : Open weights let auditors verify that safety mitigations (e.g., policy filters, bias detectors) are embedded in the network rather than black‑box post‑processing.
- Inference Logging : Every prompt–response pair can be stored with metadata (user ID, timestamp, compliance tags). In 2025, enterprises typically employ a Model Registry that version‑controls checkpoints and logs inference events to an immutable ledger (e.g., Hyperledger Fabric).
Compliance frameworks such as SOC 2 Type II, ISO 27001, and GDPR can be mapped directly onto these controls: data residency is enforced by on‑prem hosting; encryption at rest uses TPM‑backed keys; audit trails satisfy
Article 28
of the EU General Data Protection Regulation.
5. Cost Optimization Framework
Use Case
Model Variant
Token Cost (per million)
Estimated Savings vs Proprietary API
Customer Support Chatbot
Flash‑Lite
$0.24
$700K annually for 10,000 tickets
Regulatory Filing Review
Pro (on‑prem)
$0.36
$900K annually vs $1.5M API spend
Invoice Extraction (vision)
NVLM 2.5
$0.18
$250K savings on 50,000 invoices
Key takeaways:
- Deploy NVLM 2.5 for vision tasks to avoid GPU‑heavy inference costs.
- Use Gemini’s adaptive budgets: set max_tokens_per_step=256 for routine queries, raise to 1024 for compliance checks.
- Monitor token usage per endpoint; auto‑switch from Pro to Flash‑Lite when thresholds exceed 75% of budget.
6. Implementation Roadmap for Enterprise Architects
- Data & Policy Assessment : Map data residency, encryption, and compliance requirements across all use cases.
- Pilot Architecture : Build a single hybrid agent that ingests PDFs, extracts entities via NVLM 2.5, passes them to Gemini 3.0 Pro for risk scoring, and outputs a JSON‑to‑dashboard pipeline.
- Governance Layer : Deploy a policy engine (e.g., Open Policy Agent ) that enforces reasoning budgets and flags potential compliance violations before responses are returned.
- Observability Stack : Instrument inference endpoints with Prometheus metrics, log all prompts to an immutable ledger, and set up alerts for anomalous token spikes.
- Scale & Optimize : Use model parallelism (Megatron‑LM) or distill to a 12B variant if GPU memory is constrained; cache frequent embeddings to reduce inference latency.
7. Future Trends: Policy‑Wrapped Agents and Reasoning-as-a-Service
By mid‑2026, vendors are expected to ship
policy wrapper SDKs
that let enterprises inject custom compliance rules without touching the base model. These wrappers will expose a simple declarative language (similar to SQL) for specifying data access constraints, safe‑response filters, and audit logging hooks.
Simultaneously, cloud providers will offer
Reasoning-as-a-Service
, where adaptive budgets are negotiated as part of the SLA. Enterprises can lock in a guaranteed maximum token spend per month while still leveraging open models for internal workloads.
8. Strategic Recommendations
- Build a Hybrid Stack : Combine NVLM 2.5 (vision) + Gemini 3.0 Pro (reasoning) + managed Flash‑Lite for volume tasks.
- Adopt Adaptive Reasoning Budgets : Dynamically adjust max_tokens_per_step based on query complexity; tie budget limits to SLA tiers.
- Prioritize Auditability : Store every inference event in an immutable ledger; version‑control model checkpoints; maintain a policy registry that maps compliance requirements to model usage.
- Invest in Governance Infrastructure : Centralize policy enforcement, token monitoring, and bias mitigation into a single platform to reduce operational overhead.
- Launch Hybrid Agent POCs : Demonstrate ROI with end‑to‑end pipelines (document → code → visualization) in high‑value domains such as contract review or clinical trial data analysis.
In 2025, the decisive factor for enterprise AI success is not which company owns the largest model but how effectively an organization can own, govern, and scale open multimodal intelligence. By embracing NVLM 2.5, Gemini 3.0 Pro, adaptive reasoning budgets, and hybrid agent architectures, executives can achieve significant cost reductions, satisfy stringent regulatory requirements, and unlock new product capabilities that will sustain competitive advantage for years to come.
Related Articles
Anthropic appoints Irina Ghose, a former Microsoft India managing director, to lead its business in India, which has the second-largest user base for Claude (Jagmeet Singh/TechCrunch)
Explore how Anthropic’s new India strategy under Irina Ghose is reshaping enterprise AI contracts, leveraging Claude 3.5 and o1-mini for safety‑first deployments in 2026.

IBM wants to give businesses and governments more control over AI data
IBM’s Quest for Data Control: What CIOs and CTOs Must Know Meta description: Enterprise leaders face a new era of AI where data sovereignty, hybrid deployment, and compliance are non‑negotiable. This...

Enterprise Adoption of Gen AI - MIT Global Survey of 600+ CIOs
Discover how enterprise leaders can close the Gen‑AI divide with proven strategies, vendor partnerships, and robust governance.